DPO Radio
AesirX Data Discovery

![]() DATA DISCOVERY
DATA DISCOVERY
Find every data asset in your infrastructure and route it through review to your classification workflow
Discovery cycle orchestration with owner review routing, exception handling, and classification lineage integration.


Why Data Discovery Matters
Organizations cannot protect or govern data they do not know about. Undiscovered data assets – systems processing personal data without documentation, shadow databases, forgotten staging environments – represent both a compliance gap and a security risk. Regulators expect a current, complete inventory, not one that was accurate six months ago.
Data Governance Leads (P-VN-05) are responsible for maintaining the completeness of the data inventory. The Automated Data Discovery, Classification, and Labeling Review workflow (UC-VN-10) begins with discovery: scanning infrastructure, identifying data assets, and routing findings to the appropriate owners for review before they enter the classification and mapping systems.
Without a structured discovery process, inventory completeness depends on individual departments self-reporting their systems. New systems are deployed without being added to the data map. Decommissioned systems remain in the inventory long after they are gone. When a delta occurs (a new system appears or an existing one changes) no one is notified. The data inventory drifts further from reality with every quarter.
Data Discovery provides formal discovery cycle orchestration with delta detection, owner review routing with exception handling, AI-assisted classification suggestions, and direct lineage integration with the Data Classification module so every confirmed finding flows seamlessly into the classification workflow.
How It Works
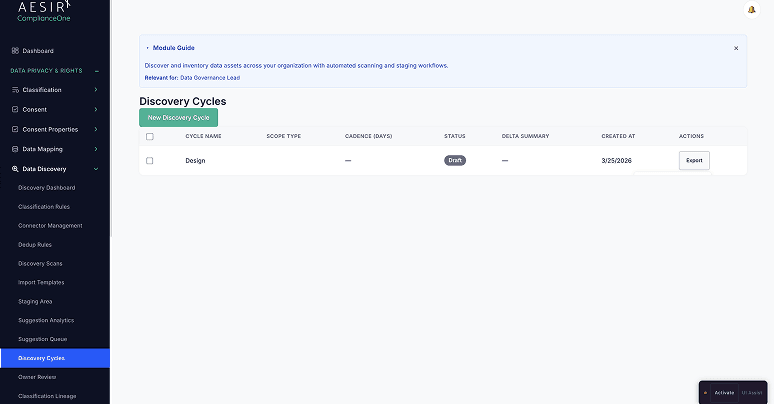
Discovery Cycle Orchestration
Create, execute, and close formal discovery cycles. Each cycle produces findings that are compared against the previous cycle's results, with delta detection highlighting what has changed – new assets discovered, existing assets modified, and previously known assets no longer detected.
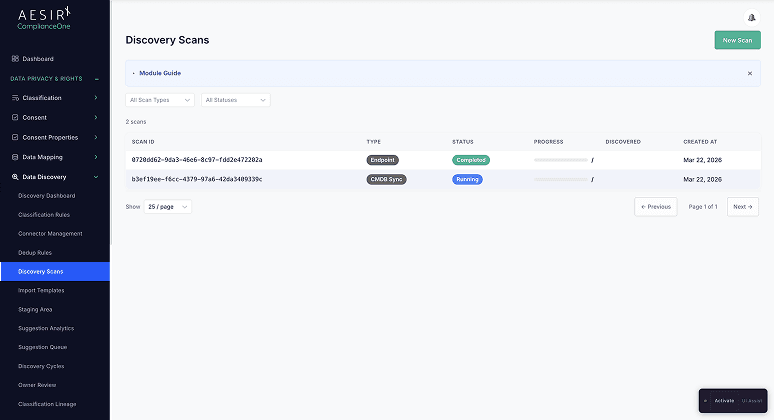
Discovery Scans
Configure and run endpoint scans across your infrastructure. Scans identify data assets, systems, and endpoints that may be processing personal data, feeding results into the staging area for review.
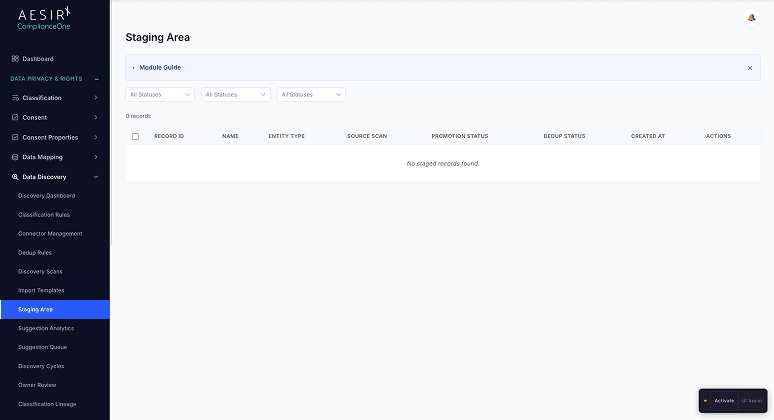
Staging Area
Discovered systems are held in a staging area before being added to the official inventory. This review step prevents false positives and duplicates from contaminating the data map, while ensuring legitimate findings are not lost.
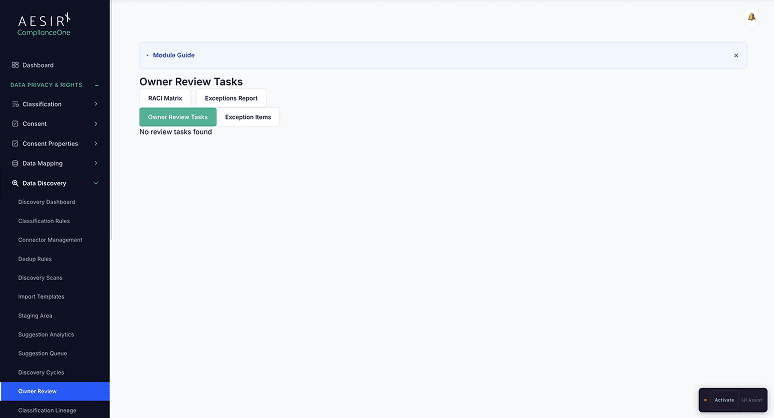
Owner Review Routing with Exception Handling
Discovered assets are routed to the appropriate data owner for review based on organizational hierarchy. When an asset cannot be automatically assigned to an owner, or when the owner disputes the finding, the exception is surfaced in a dedicated queue for DPO resolution.
Deduplication Rules
Configurable deduplication rules prevent duplicate system records from entering the inventory. When a scan identifies an asset that matches an existing record, the deduplication engine flags it rather than creating a duplicate.
AI-Assisted Classification Suggestions
Confidence-scored classification recommendations help reviewers categorize discovered assets. Suggestions are based on patterns identified during scanning and are presented as recommendations, the final classification decision remains with the data owner.
Classification Lineage Integration
Confirmed discoveries flow directly into the Data Classification workflow. Each asset maintains an auditable lineage from the original scan finding through owner review to the approved classification label, ensuring traceability across the entire discovery-to-classification pipeline.
Import Templates and Connector Integration
Bulk import from spreadsheets supports initial inventory population or migration from legacy systems. Connector integration enables discovery through connected external systems, expanding coverage beyond direct endpoint scanning.
Compare the Difference

Without Data Discovery

With Data Discovery
Built for Real Compliance Operations

Discovery cycle orchestration with delta detection ensures that every cycle produces actionable results, not just a full inventory dump, but a focused view of what has changed since the last review.

Owner review routing with exception handling ensures that every discovered asset is assigned to a responsible person, and findings that cannot be automatically assigned are escalated rather than dropped.

Classification lineage integration maintains an auditable chain from scan finding through owner review to approved classification label, supporting regulators who ask not just "what data do you have" but "how did you determine its classification."




See Data Discovery in Action
Ready to see how Data Discovery works with your compliance workflows? Request a personalized demo.


Ronni K. Gothard Christiansen - Technical Privacy Engineer & CEO
Technical Compliance Expert, 32+ Years Open Source Advocate, X-BoD Open Source Matters Inc.
People Also Ask
Discovery cycle frequency depends on your organization's rate of change. The module supports configurable cycle scheduling – organizations with frequent system deployments may run monthly cycles, while more stable environments may use quarterly cycles. Each cycle's delta detection shows exactly what changed.
The asset is routed to the exception queue. Exceptions are surfaced for DPO resolution, ensuring that no finding is silently dropped. The DPO can assign ownership, investigate further, or escalate as needed.
Configurable deduplication rules match discovered assets against existing inventory records. When a scan identifies an asset that appears to match an existing record, the deduplication engine flags it for review rather than creating a duplicate entry.
Yes. Import templates support bulk import from spreadsheets, enabling migration from legacy inventory systems or initial population from existing documentation. Imported records enter the staging area for verification before being added to the official inventory.
Confirmed discoveries flow directly into the Data Classification module. Each asset maintains an auditable lineage from the original scan finding through owner review to its approved classification label. This lineage is preserved in the audit trail and can be provided to regulators.
Next Steps
Explore the module architecture, then speak with us about the workflows your organization needs to operationalize first.

Start a Compliance Pilot
Run a discovery cycle against your actual infrastructure and see the findings-to-classification pipeline.

Discuss Your Compliance Needs
Walk through your infrastructure landscape, discovery frequency, and integration requirements with our team.

The evolution of Aesir is Aesir + ![]() (the Norse symbol for Necessity)"Needed in order to achieve a particular result"
(the Norse symbol for Necessity)"Needed in order to achieve a particular result"
♥Join the AesirX Privacy Newsletter. Stay Informed. Stay Compliant.


