DPO Radio
Classification

![]() CLASSIFICATION
CLASSIFICATION
Apply consistent sensitivity labels across your organization with approval gates and owner accountability
Sensitivity labeling with proposed/approved workflows, exception queues, and an enterprise data map for executive reporting.


Why Classification Matters
Regulators expect organizations to know the sensitivity of the data they hold. Under Vietnam's PDPL and the Vietnam Data Law, certain categories of personal data – health, biometric, financial, children's data – carry additional processing restrictions and protection obligations. An organization that cannot demonstrate consistent, approved classification of its data assets is exposed to findings in any regulatory inspection.
Data Governance Leads (P-VN-05) are responsible for establishing classification schemes, reviewing proposed labels, and maintaining an enterprise-wide view of how data is classified across departments. This role drives the Automated Data Discovery, Classification, and Labeling Review workflow (UC-VN-10), which depends on classification labels being accurate, approved, and linked to the underlying data inventory.
Without a structured classification system, sensitivity labels are applied informally or not at all. Different departments use different terminology for the same sensitivity level. When a new dataset is discovered, no one is routed to review and approve its classification. Exceptions and conflicts – where a dataset could reasonably carry more than one label – go unresolved. Leadership has no consolidated view of how data is classified across the business, making risk-based decisions difficult.
Classification provides custom taxonomy building, a label approval workflow with proposed/approved lifecycle, owner review routing based on organizational hierarchy, an exception queue for conflicts, and an enterprise data map with department-level drill-down for executive reporting.
How It Works
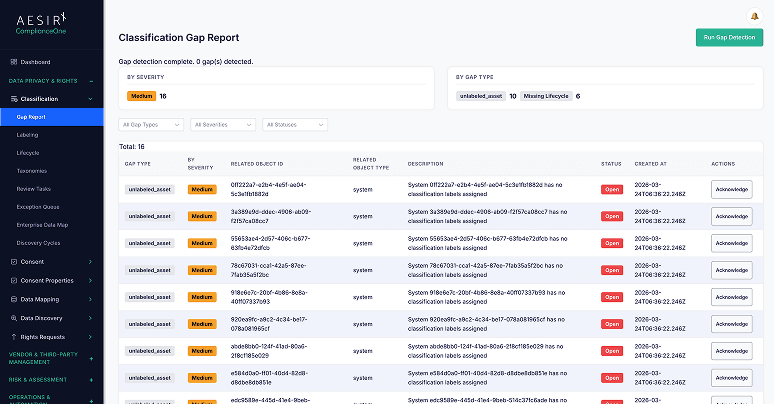
Gap Report
Identify unlabelled assets, missing lifecycle states, and classification gaps across systems. Track status, severity, and remediation actions to support audit readiness and structured resolution.
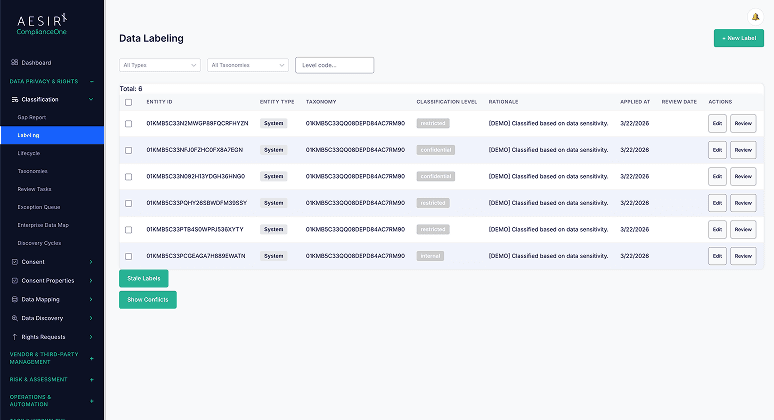
Sensitivity Labeling
Apply classification labels to systems and datasets. Labels link to the taxonomy and carry metadata about who applied them, when, and under what authority. Bulk operations allow labels to be applied to multiple assets at once.
Label Approval Workflow
New labels move through a proposed/approved lifecycle. When a label is proposed, it is routed to the appropriate data owner for review based on organizational hierarchy. The label does not take effect until the owner approves it, preventing unauthorized or incorrect classifications from being applied.
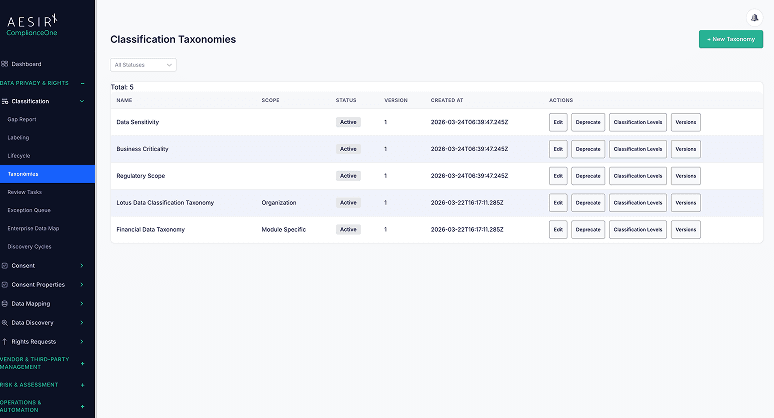
Taxonomy Builder
Create custom classification schemes that match your organization's requirements, for example, Public, Internal, Confidential, and Restricted. Taxonomies define the available sensitivity levels and their definitions, ensuring consistent terminology across the enterprise.
Owner Review Routing
Proposed labels are automatically routed to the correct data owner based on the organizational hierarchy associated with the asset. This ensures that the person accountable for the data makes the classification decision, not an unrelated administrator.
Exception Queue
Classification conflicts – where an asset could reasonably carry more than one label, or where a proposed label conflicts with existing classifications – are surfaced in a dedicated exception queue. Exceptions escalate to the appropriate data owner or DPO for resolution.
Enterprise Data Map
A consolidated organization-wide view of all classified assets with department-level drill-down. The enterprise data map gives leadership visibility into how data is classified across the business, supporting risk-based decisions and executive reporting.
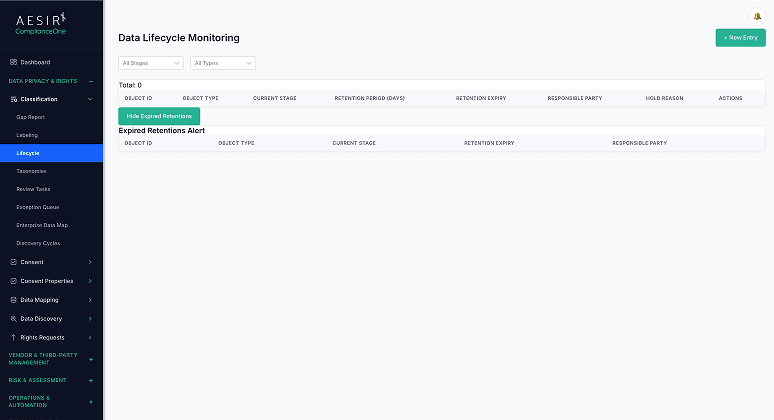
Discovery Cycles
Confirmed discoveries from the Data Discovery module flow into the classification workflow. When a new data asset is discovered, it enters the labeling and approval process automatically, maintaining an auditable lineage from scan finding to approved classification label.
Compare the Difference

Without Classification
With Classification
Built for Real Compliance Operations

The proposed/approved label lifecycle ensures that no classification takes effect without explicit owner review, creating a documented decision record for every sensitivity label in the enterprise.

The exception queue prevents classification conflicts from being silently ignored – every conflict is surfaced, assigned, and resolved with an audit trail showing who decided and why.

The enterprise data map consolidates classification state across all departments into a single view, enabling leadership to identify concentrations of sensitive data without requesting reports from individual teams.



Regulatory Framework Support
Framework
How Classification Supports It

See Classification in Action
Ready to see how Classification works with your compliance workflows? Request a personalized demo.


Ronni K. Gothard Christiansen - Technical Privacy Engineer & CEO
Technical Compliance Expert, 32+ Years Open Source Advocate, X-BoD Open Source Matters Inc.
People Also Ask
You define your own classification schemes using the taxonomy builder. Whether your organization uses three levels or seven, the taxonomy captures your specific sensitivity definitions and is applied consistently across all labeling operations.
Every new label enters a proposed state and is routed to the data owner responsible for the asset based on organizational hierarchy. The label does not take effect until the owner reviews and approves it. This prevents unauthorized classifications from being applied.
When an asset could reasonably carry more than one label, or when a proposed label conflicts with existing classifications, the conflict is surfaced in the exception queue. It escalates to the data owner or DPO for documented resolution.
When the Data Discovery module identifies a new data asset, it flows into the classification workflow automatically. The asset enters the labeling and approval process, maintaining an auditable lineage from scan finding to approved classification label.
The enterprise data map provides a consolidated organization-wide view of all classified assets with department-level drill-down. Leadership can see how data is classified across every business unit without requesting individual department reports.
Next Steps
Explore the module architecture, then speak with us about the workflows your organization needs to operationalize first.

Start a Compliance Pilot
Test Classification with your actual taxonomies, assets, and approval workflows in a guided pilot.

Discuss Your Compliance Needs
Walk through your classification requirements, organizational structure, and reporting needs with our team.

The evolution of Aesir is Aesir + ![]() (the Norse symbol for Necessity)"Needed in order to achieve a particular result"
(the Norse symbol for Necessity)"Needed in order to achieve a particular result"
♥Join the AesirX Privacy Newsletter. Stay Informed. Stay Compliant.


